Decoding Visual Experience and Mapping Semantics through Whole-Brain Analysis Using fMRI Foundation Models
Coming soon...
- Yanchen Wang *1
- Adam Turnbull *1
- Tiange Xiang 2
- Yunlong Xu 3
- Sa Zhou 1
- Adnan Masoud 4
- Shekoofeh Azizi 5
- Feng Vankee Lin †1
- Ehsan Adeli †1,2
- 1Standford University, Department of Psychiatry and Behavioral Sciences
- 2Standford University, Department of Computer Science
- 3The University of Chicago, Department of Neurobiology
- 4UST
- 5Google DeepMind
- *Equal Contribution †Equal Senior Authorship



Overview
Abstract
Neural decoding, the process of understanding how brain activity corresponds to different stimuli, has been a primary objective in cognitive sciences. Over the past three decades, advancements in functional Magnetic Resonance Imaging (fMRI) and machine learning have greatly improved our ability to map visual stimuli to brain activity, especially in the visual cortex. Concurrently, research has expanded into decoding more complex processes like language and memory across the whole brain, utilizing techniques to handle greater variability and improve signal accuracy. We argue that "seeing" involves more than just mapping visual stimuli onto the visual cortex; it engages the entire brain, as various emotions and cognitive states can emerge from observing different scenes. In this paper, we develop AI algorithms to enhance our understanding of visual processes by incorporating whole-brain activation maps while individuals are exposed to visual stimuli. We utilize large-scale fMRI encoders and Image generative models (encoders & decoders) pre-trained on large public datasets, which are then fine-tuned through Image-fMRI contrastive learning. Our models hence can decode visual experience across the entire cerebral cortex, surpassing the traditional confines of the visual cortex. Using a public dataset (BOLD5000), we first compare our method with state-of-the-art approaches to decoding visual processing and show improved predictive semantic accuracy by 43%. Further analyses suggest that higher cortical regions contribute more to decoding complex visual scenes. Additionally, we implemented zero-shot imagination decoding on an extra validation dataset, achieving a p-value of 0.0206, which substantiates the model's capability to capture semantic meanings across various scenarios. These findings underscore the potential of employing comprehensive models in enhancing the nuanced interpretation of semantic processes.
Highlights
- Whole-brain scale visual decoding using fMRI data.
- SOTA 50-way top-1 classification accuracy (semantic) on BOLD5000 dataset, surpassing the previous best by 43%.
- Succesfully Decode the images without visual network (Yeo 7 networks).
- Whole brain clustering analysis shows that higher cortical regions contribute more to decoding complex visual scenes.
- Validation on an extra dataset with zero-shot imagination decoding, achieving a p-value of 0.0206.
WAVE
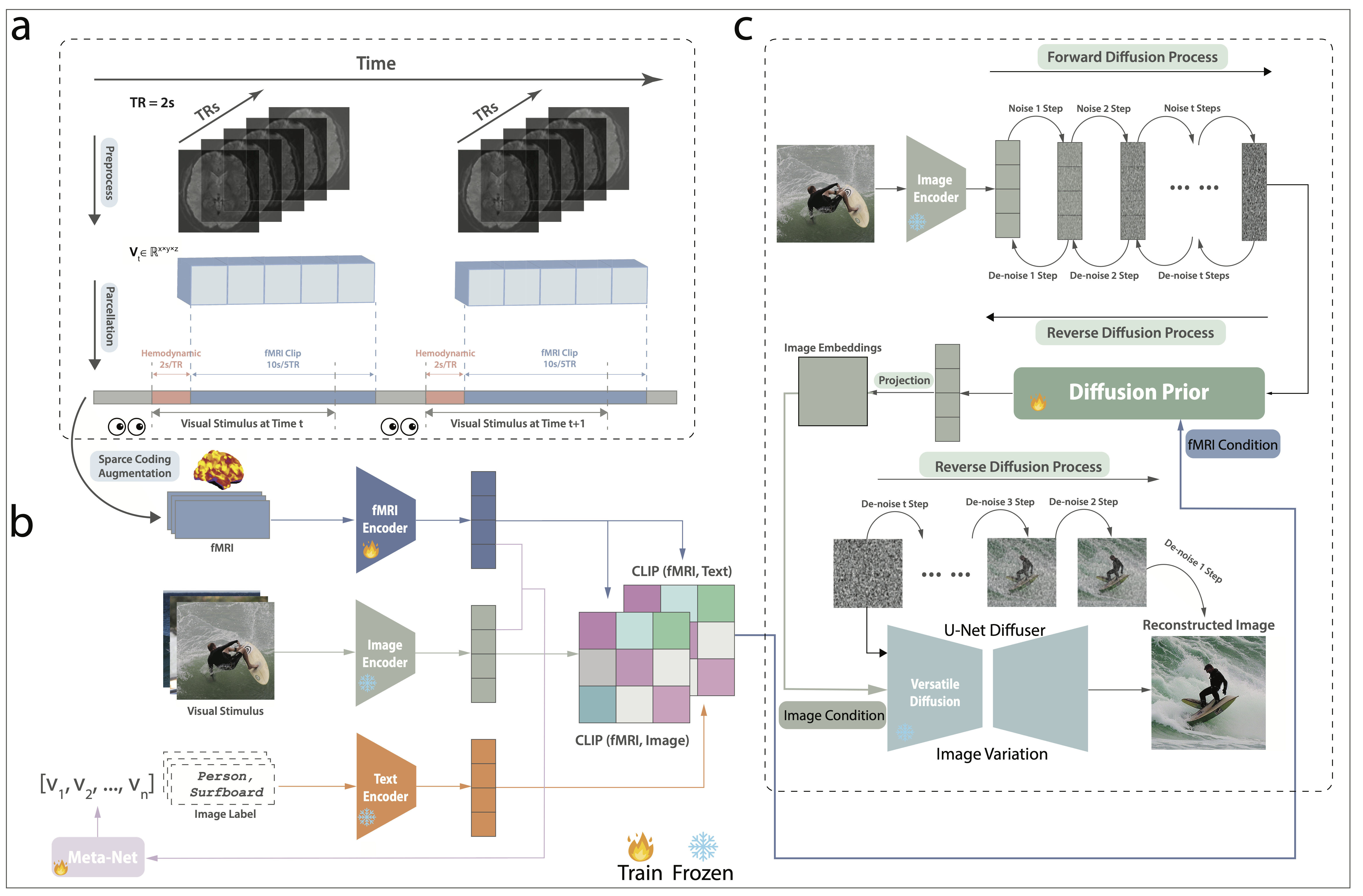
The depicted architecture illustrates a two-part training approach for the model. Part A focuses on contrastive learning, where knowledge is distilled using three modalities: fMRI, text, and images. Part B advances to diffusion model training, fine-tuning a specialized prior to transform fMRI latents into image latents. Icons of locks indicate modules that were frozen during the training phase.
Results

Comparison of fMRI data decoding using WAVE and other advanced methods. a, Reconstructed images using individual model settings for WAVE (Whole Brain), MindEye, and Mind-Vis across the fMRI visual cortex. b, Universal settings across all four subjects in the BOLD5000 dataset. This panel demonstrates the generalization capability of WAVE, MindEye, and Mind-Vis among different subjects. c, The saliency map of whole visual network masked WAVE model, which showed the top 25% regions of interests. d, Reconstructed images from masked visual network fMRI data. We set the visual region values to 0 as a masked. The visual cortex masked reconstructed image semantic accuracy is 18.98% averaged across 4 subjects.
Whole Brain Clustering Analysis
Visualization of Post-Hoc Whole-Brain Visual Clustering Analysis. a, t-SNE visualization of image embeddings, differentiated by five clusters identified via K-Means, each represented in unique colors. b-f, Each subfigure presents word clouds generated from image labels, with word sizes proportional to their frequency of occurrence within the cluster. The subfigure titles, generated by ChatGPT-4, summarize the thematic essence of each cluster. Accompanying each word cloud are selected image samples and a whole-brain saliency map highlighting the top 20 regions of interest relevant to the cluster. h, Quantitative analysis showing the distribution of regions across the Yeo 7 networks for each of the five clusters, providing insights into the network-based localization of visual processing associated with different categories.
Zero-Shot Imagination Decoding
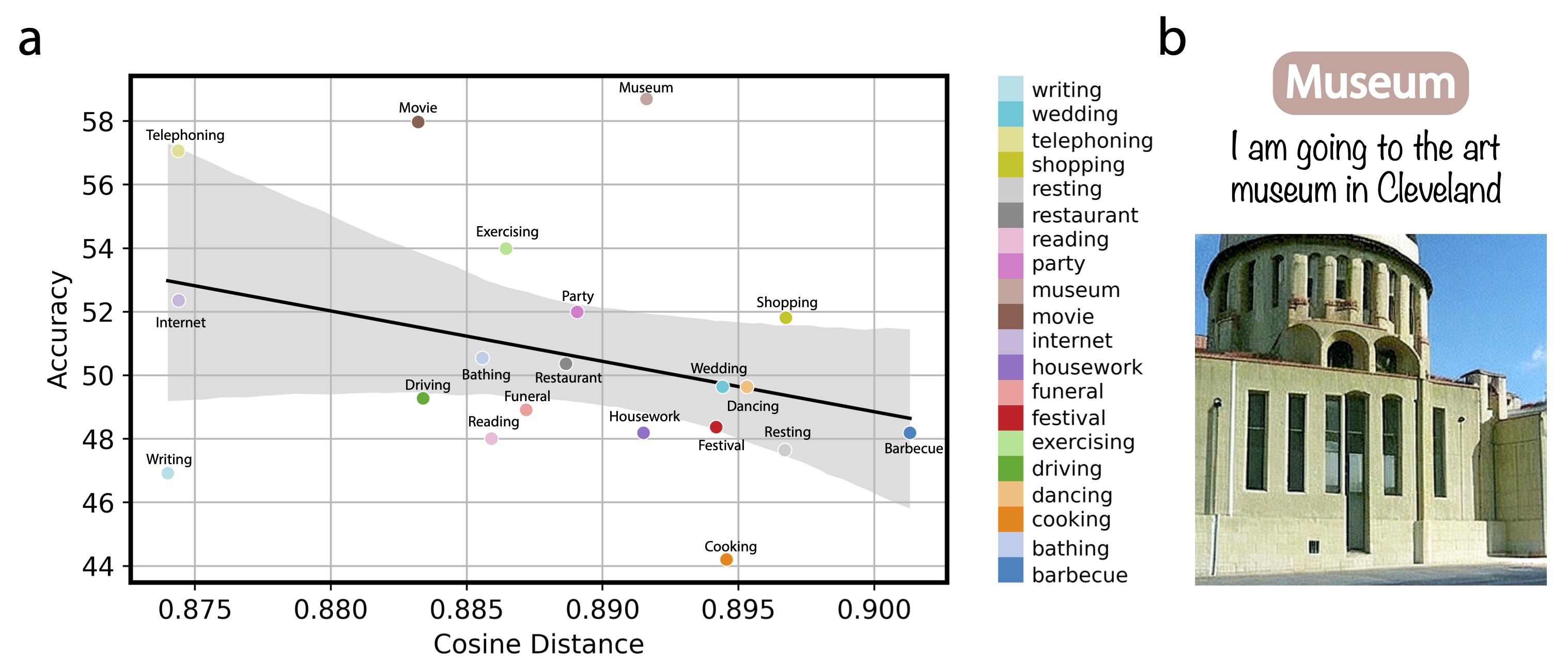
WAVE Zero-Shot brain imagination decoding results a, Scenario-based scale analysis utilizing two-way-identification accuracy. This analysis measures the cosine distance of each scenario's features to those in the training dataset~(BOLD5000), showing how scenario proximity affects decoding accuracy. b, Example of WAVE model zero-shot reconstructed images from imagination recording fMRI sessions. The text stimuli describing the museum scenario is presented above the example image, illustrating the model's capability to generate visual reconstructions based on described scenarios.
BibTeX
If you find our data or project useful in your research, please cite:
@article{wang2024decoding,
title={Decoding Visual Experience and Mapping Semantics through Whole-Brain Analysis Using fMRI Foundation Models},
author={Wang, Yanchen and Turnbull, Adam and Xiang, Tiange and Xu, Yunlong and Zhou, Sa and Masoud, Adnan and Azizi, Shekoofeh and Lin, Feng Vankee and Adeli, Ehsan},
journal={arXiv preprint arXiv:2411.07121},
year={2024}
}